Carl R. Woese Postdoctoral Fellow
University of Illinois Urbana-Champaign
About me
Hi, I am a postdoctoral fellow at the Carl R. Woese Institute for Genomic Biology (IGB) at the University of Illinois Urbana-Champaign (UIUC). I am currently working in genomic security and privacy with Prof. Carl Gunter and Prof. Olgica Milenkovic. Previously, I completed my MS and PhD degrees in the Ming Hsieh Department of Electrical and Computer Engineering at the University of Southern California, working under the guidance of Prof. Salman Avestimehr in the Information Theory and Machine Learning (vITAL) research lab. During my research pursuits, I have also collaborated closely with Prof. Murali Annavaram, Prof. Keith Chugg, and Prof. Ramtin Pedarsani. I have also had the fortune to gain industry experience through multiple internships. I spent Summer 2018 and Summer 2019 as a Research Intern at Intel Labs under Dr. Shilpa Talwar and Dr. Nageen Himayat respectively. During Summer 2021, I was an Applied Scientist Intern at Amazon Alexa AI under Dr. Clement Chung and Dr. Rahul Gupta. Prior to joining the graduate school, I completed my BTech in 2016 in Electrical Engineering from the Indian Institute of Technology Kanpur, where I worked under Prof. Aditya K. Jagannatham, in the Multimedia Wireless Networks (MWN) Group.
Outside research, I like hanging out with friends, watching classical Bollywood movies, and listening to Indian classical music.
(CV available upon request)
- Distributed Optimization and Learning
- Security and Privacy in Data Analytics
- Biological Data Modeling and Analysis
- Information and Coding Theory
-
MS/PhD in Electrical and Computer Engineering, 2022
University of Southern California
-
BTech in Electrical Engineering, 2016
Indian Institute of Technology Kanpur
Professional
Experience
Projects
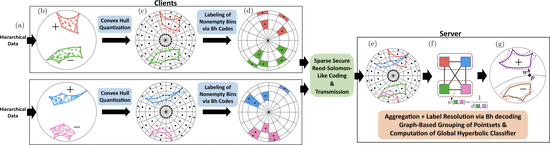
Federated Classification in Hyperbolic Spaces via Secure Aggregation of Convex Hulls
Proposed the first approach to enable privacy-preserving classification in hyperbolic geometry in the federated setting.

Machine Unlearning of Federated Clusters
Proposed the first known unlearning mechanism for federated clustering with privacy criteria that support simple, provable, and efficient data removal at the client and server level.
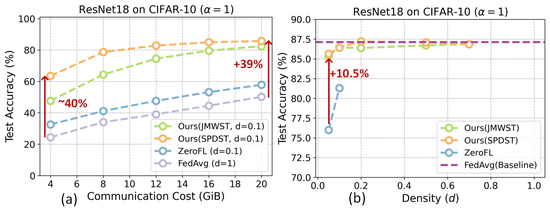
Lottery Aware Sparse Federated Learning
Presented methodologies for sparse federated learning for resource constrained edge (both homogeneous and heterogeneous compute budget).
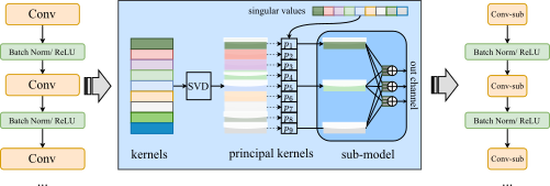
Resource-Constrained Federated Learning of Large Models
Provided a sub-model training method that enabled resource-constrained clients to train large models in federated learning settings.
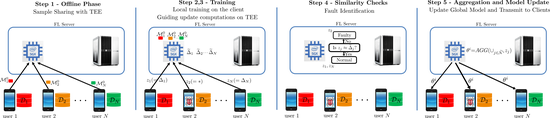
Secure and Fault Tolerant Decentralized Learning
Proposed a novel sampling based approach that applies per client criteria for mitigating faults in the general federated learning setting.
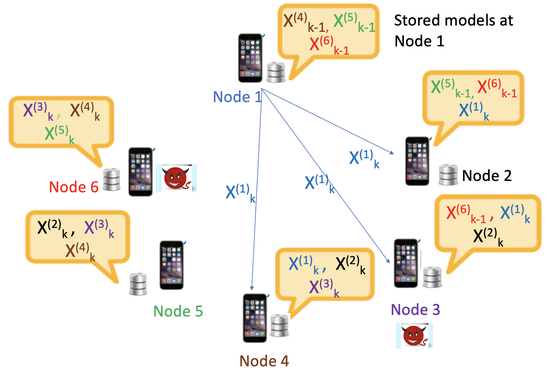
Secure Large-Scale Serveless Training at the Edge
Developed a fast and computationally efficient Byzantine robust algorithm that leverages a sequential, memory assisted and performance criteria for training over a logical ring.
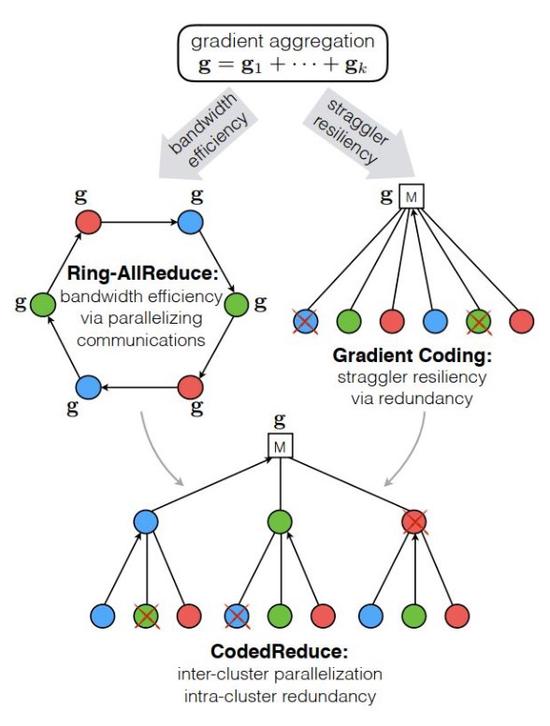
Fast and Robust Large-Scale Distributed Gradient Descent
Developed a practical algorithm for distributed learning that is both communication efficient and straggler-resilient.
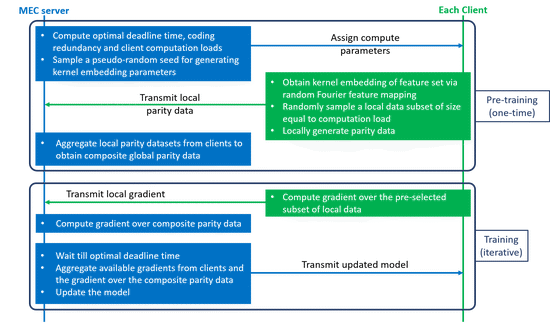
Low-Latency Federated Learning in Wireless Edge Networks
Proposed CodedFedL that injects structured coding redundancy into non-linear federated learning for mitigating stragglers and speeding up training procedure in heterogeneous MEC networks.
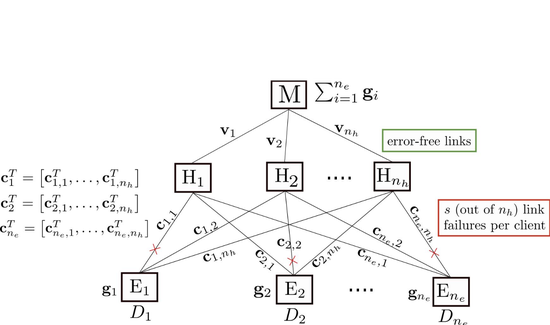
Hierarchical Decentralized Training at the Edge
Formulated a problem for decentralized training from data at the edge users, incorporating the challenges of straggling communications and limited communication bandwidth.
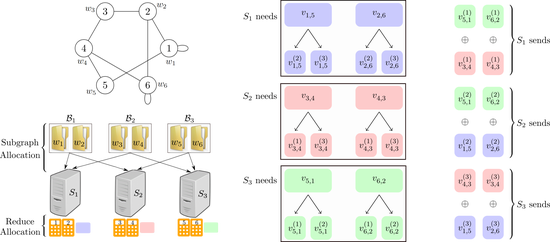
Communciation Efficient Large-Scale Graph Processing
Proposed and implemented a practical MapReduce based approach for large-scale graph processing.
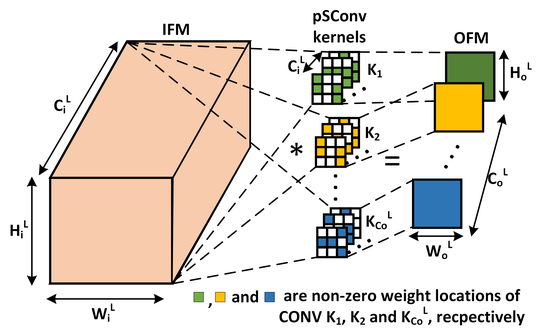
Pre-defined Sparsity for Convolutional Neural Networks
Proposed the first approach to reduce footprint of convolutional neural networks via pre-defined sparsity.
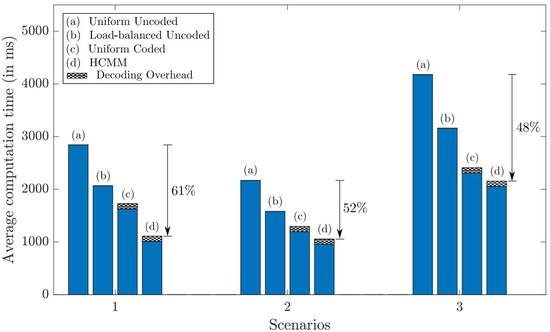
Optimal Resource Allocation for Cloud Computing
Developed an efficient approach for load allocation in heterogeneous cloud clusters.
Publications
Journals
Preprints
Conferences
Other
Proceedings
Workshops
Selected
Talks
Selected
Awards
Contact
- sauravp2@illinois.edu
- +1 213-245-9100
- 2122, Carl R. Woese Institute for Genomic Biology, UIUC, Urbana, IL 61801
- DM Me